Aug 17, 2010
Parallel LDA Gibbs Sampling Using OpenMP and MPI
I created an open source project, ompi-lda, on Google Code. This project is inspired by another LDA project which I initialized at Google and a recent parallel programming effort using OpenMP by xlvector.
Jun 28, 2010
I Moved My Blog to Wordpress
Since I found it is convenient to insert code and LaTeX math into my posts using Wordpress, I moved this blog to
I may no longer update this blog.
I may no longer update this blog.
Jun 21, 2010
Google Protocol Buffers 实用技术:
解析.proto文件和任意数据文件
Google Protocol Buffers 是一种非常方便高效的数据编码方式(data serialization),几乎在Google的每个产品中都用到了。本文介绍 protocol buffers 的一种高级使用方法(在Google Protocol Buffer的主页上没有的)。
Protocol Buffers 通常的使用方式如下:我们的程序只依赖于有限的几个 protocol messages。我们把这几个 message 定义在一个或者多个 .proto 文件里,然后用编译器 protoc 把 .proto 文件翻译成 C++ 语言(.h和.cc文件)。这个翻译过程把每个 message 翻译成了一个 C++ class。这样我们的程序就可以使用这些 protocol classes 了。
但是还有一种不那么常见的使用方式:我们有一批数据文件(或者网络数据流),其中包含了一些 protocol messages 内容。我们也有定义这些 protocol messages 的 .proto 文件。我们希望解析数据文件中的内容,但是不能使用 protoc 编译器。
一个例子是 codex。codex是Google内最常用的一个工具程序。它可以解析任意文件中的 protocol message 内容,并且把这些内容打印成人能方便的阅读的格式。为了能正确解析和打印数据文件内容,codex 需要定义 protocol message 的 .proto 文件。
为了实现 codex 的功能,一种ad hoc的方法是:
1 把 codex 的基本功能(比如读取数据文件,打印文件内容等)实现在一个 .cc 文件里(比如叫做 codex-base.cc)
1 对给定的 .proto 文件,调用 protoc,得到对应的 .pb.h 和 .pb.cc 文件。
1 把 codex-base.cc 和 protoc 的结果一起编译,生成一个专门解析某一个 protocol message 内容的 codex 程序。
这个办法太ad hoc了。它为每个 .protoc 文件编写一个 codex 程序。
另一个办法是,如果我们有世界上所有的 .proto 文件,那么我们把它们都预先用 protoc 编译了,链接进 codex。显然这个搞法也是不现实的。
那么codex到底是怎么实现的呢?其实它利用了 protocol buffers 没有写入文档的一些 API。闲话少说,我们来看一段用这些“神秘的API“写的代码。这段代码用于解析任意给定的 .proto 文件:
以上代码中利用了 DescriptorPool 从 FileDescriptorProto 解析出 FileDescriptor(描述 .proto 文件中所有的 messages)。然后用 DynamicMessageFactory 从 FileDescriptor 里找到我们关注的那个 message 的 MessageDescriptor。接下来,我们利用 DynamicMessageFactory 根据 MessageDescriptor 得到一个 prototype message instance。注意,这个 instance 是不能往里面写内容的(immutable)。我们需要调用其 New 成员函数,来生成一个 mutable 的 instance。
有了一个对应数据记录的 message instance,接下来就好办了。我们读取数据文件中的每条记录。注意:此处我们假设数据文件中以此存放了一条记录的长度,然后是记录内容,接下来是第二条记录的长度和内容,以此类推。所以在上述函数中,我们循环的读取记录长度,然后解析记录内容。值得注意的是,解析内容利用的是 mutable message instance 的 ParseFromArrary 函数;它需要知道记录的长度。因此我们必须在数据文件中存储每条记录的长度。
接下来这段程序演示如何调用 GetMessageTypeFromProtoFile 和 PrintDataFile:
Protocol Buffers 通常的使用方式如下:我们的程序只依赖于有限的几个 protocol messages。我们把这几个 message 定义在一个或者多个 .proto 文件里,然后用编译器 protoc 把 .proto 文件翻译成 C++ 语言(.h和.cc文件)。这个翻译过程把每个 message 翻译成了一个 C++ class。这样我们的程序就可以使用这些 protocol classes 了。
但是还有一种不那么常见的使用方式:我们有一批数据文件(或者网络数据流),其中包含了一些 protocol messages 内容。我们也有定义这些 protocol messages 的 .proto 文件。我们希望解析数据文件中的内容,但是不能使用 protoc 编译器。
一个例子是 codex。codex是Google内最常用的一个工具程序。它可以解析任意文件中的 protocol message 内容,并且把这些内容打印成人能方便的阅读的格式。为了能正确解析和打印数据文件内容,codex 需要定义 protocol message 的 .proto 文件。
为了实现 codex 的功能,一种ad hoc的方法是:
1 把 codex 的基本功能(比如读取数据文件,打印文件内容等)实现在一个 .cc 文件里(比如叫做 codex-base.cc)
1 对给定的 .proto 文件,调用 protoc,得到对应的 .pb.h 和 .pb.cc 文件。
1 把 codex-base.cc 和 protoc 的结果一起编译,生成一个专门解析某一个 protocol message 内容的 codex 程序。
这个办法太ad hoc了。它为每个 .protoc 文件编写一个 codex 程序。
另一个办法是,如果我们有世界上所有的 .proto 文件,那么我们把它们都预先用 protoc 编译了,链接进 codex。显然这个搞法也是不现实的。
那么codex到底是怎么实现的呢?其实它利用了 protocol buffers 没有写入文档的一些 API。闲话少说,我们来看一段用这些“神秘的API“写的代码。这段代码用于解析任意给定的 .proto 文件:
#include <google/protobuf/descriptor.h>这个函数的输入是一个 .proto 文件的文件名。输出是一个 FileDescriptorProto 对象。这个对象里存储着对 .proto 文件解析之后的结果。我们接下来用这些结果动态生成某个 protocol message 的 instance(或者用C++术语叫做object)。然后可以调用这个 instance 自己的 ParseFromArray/String 成员函数,来解析数据文件中的每一条记录的内容。请看如下代码:
#include <google/protobuf/dynamic_message.h>
#include <google/protobuf/io/zero_copy_stream_impl.h>
#include <google/protobuf/io/tokenizer.h>
#include <google/protobuf/compiler/parser.h>
//-----------------------------------------------------------------------------
// Parsing given .proto file for Descriptor of the given message (by
// name). The returned message descriptor can be used with a
// DynamicMessageFactory in order to create prototype message and
// mutable messages. For example:
/*
DynamicMessageFactory factory;
const Message* prototype_msg = factory.GetPrototype(message_descriptor);
const Message* mutable_msg = prototype_msg->New();
*/
//-----------------------------------------------------------------------------
void GetMessageTypeFromProtoFile(const string& proto_filename,
FileDescriptorProto* file_desc_proto) {
using namespace google::protobuf;
using namespace google::protobuf::io;
using namespace google::protobuf::compiler;
FILE* proto_file = fopen(proto_filename.c_str(), "r");
{
if (proto_file == NULL) {
LOG(FATAL) << "Cannot open .proto file: " << proto_filename;
}
FileInputStream proto_input_stream(fileno(proto_file));
Tokenizer tokenizer(&proto_input_stream, NULL);
Parser parser;
if (!parser.Parse(&tokenizer, file_desc_proto)) {
LOG(FATAL) << "Cannot parse .proto file:" << proto_filename;
}
}
fclose(proto_file);
// Here we walk around a bug in protocol buffers that
// |Parser::Parse| does not set name (.proto filename) in
// file_desc_proto.
if (!file_desc_proto->has_name()) {
file_desc_proto->set_name(proto_filename);
}
}
//-----------------------------------------------------------------------------这个函数需要三个输入:1)数据文件的文件名,2)之前GetMessageTypeFromProtoFile函数返回的FileDescriptorProto对象,3)数据文件中每条记录的对应的protocol message 的名字(注意,一个 .proto 文件里可以定义多个 protocol messages,所以我们需要知道数据记录对应的具体是哪一个 message)。
// Print contents of a record file with following format:
//
// { <int record_size> <KeyValuePair> }
//
// where KeyValuePair is a proto message defined in mpimr.proto, and
// consists of two string fields: key and value, where key will be
// printed as a text string, and value will be parsed into a proto
// message given as |message_descriptor|.
//-----------------------------------------------------------------------------
void PrintDataFile(const string& data_filename,
const FileDescriptorProto& file_desc_proto,
const string& message_name) {
const int kMaxRecieveBufferSize = 32 * 1024 * 1024; // 32MB
static char buffer[kMaxRecieveBufferSize];
ifstream input_stream(data_filename.c_str());
if (!input_stream.is_open()) {
LOG(FATAL) << "Cannot open data file: " << data_filename;
}
google::protobuf::DescriptorPool pool;
const google::protobuf::FileDescriptor* file_desc =
pool.BuildFile(file_desc_proto);
if (file_desc == NULL) {
LOG(FATAL) << "Cannot get file descriptor from file descriptor"
<< file_desc_proto.DebugString();
}
const google::protobuf::Descriptor* message_desc =
file_desc->FindMessageTypeByName(message_name);
if (message_desc == NULL) {
LOG(FATAL) << "Cannot get message descriptor of message: " << message_name;
}
google::protobuf::DynamicMessageFactory factory;
const google::protobuf::Message* prototype_msg =
factory.GetPrototype(message_desc);
if (prototype_msg == NULL) {
LOG(FATAL) << "Cannot create prototype message from message descriptor";
}
google::protobuf::Message* mutable_msg = prototype_msg->New();
if (mutable_msg == NULL) {
LOG(FATAL) << "Failed in prototype_msg->New(); to create mutable message";
}
uint32 proto_msg_size; // uint32 is the type used in reocrd files.
for (;;) {
input_stream.read((char*)&proto_msg_size, sizeof(proto_msg_size));
if (proto_msg_size > kMaxRecieveBufferSize) {
LOG(FATAL) << "Failed to read a proto message with size = "
<< proto_msg_size
<< ", which is larger than kMaxRecieveBufferSize ("
<< kMaxRecieveBufferSize << ")."
<< "You can modify kMaxRecieveBufferSize defined in "
<< __FILE__;
}
input_stream.read(buffer, proto_msg_size);
if (!input_stream)
break;
if (!mutable_msg->ParseFromArray(buffer, proto_msg_size)) {
LOG(FATAL) << "Failed to parse value in KeyValuePair:" << pair.value();
}
cout << mutable_msg->DebugString();
}
delete mutable_msg;
}
以上代码中利用了 DescriptorPool 从 FileDescriptorProto 解析出 FileDescriptor(描述 .proto 文件中所有的 messages)。然后用 DynamicMessageFactory 从 FileDescriptor 里找到我们关注的那个 message 的 MessageDescriptor。接下来,我们利用 DynamicMessageFactory 根据 MessageDescriptor 得到一个 prototype message instance。注意,这个 instance 是不能往里面写内容的(immutable)。我们需要调用其 New 成员函数,来生成一个 mutable 的 instance。
有了一个对应数据记录的 message instance,接下来就好办了。我们读取数据文件中的每条记录。注意:此处我们假设
接下来这段程序演示如何调用 GetMessageTypeFromProtoFile 和 PrintDataFile:
int main(int argc, char** argv) {
string proto_filename, message_name;
vector<string> data_filenames;
FileDescriptorProto file_desc_proto;
ParseCmdLine(argc, argv, &proto_filename, &message_name, &data_filenames);
GetMessageTypeFromProtoFile(proto_filename, &file_desc_proto);
for (int i = 0; i < data_filenames.size(); ++i) {
PrintDataFile(data_filenames[i], file_desc_proto, message_name);
}
return 0;
}
Jun 10, 2010
Intel’s Single-chip Cluster Computer
I just read a post on Intel's single-chip cluster computer. This is really a unique thing: multiple cores in a chip, each core has its own private-and-fast memory: cache. Main memory becomes more like the NFS. Programmers write programs for this chip using MPI.
So, this chip is a cluster with super-fast network connection (64GB/s) and very limited memory (because they are implemented as cache).
So, this chip is a cluster with super-fast network connection (64GB/s) and very limited memory (because they are implemented as cache).
Jun 5, 2010
How to Install Dropbox in Ubuntu Using SOCKS Proxy
As a Chinese, I live behind the G.F.W. and have to get access Internet through an SSH tunnel. However, the Dropbox installation procedure do not support either SOCKS5 or http proxy. (Yes, the document says it works with http_proxy environment variable, but seems it does not.) Thanks to two great tools: proxychains and tsocks, which can launch any application and handle their network communication request through a pre-configured proxy. With the help of these tools, I can install Dropbox on a brand new Ubuntu machine behind the G.F.W. Here follows the steps:
- Install tsocks (or proxychains) under Ubuntu using synaptic. Thanks to Ubuntu, who made these tools standard packages.
- Get a SSH tunnel (in any way you like). I paid for an account. So I can setup a proxy tunnel by the following command line on my computer:
ssh -D 7070 my-username@my-service-provider-url
- Configure your Web browser to use the tunnel. In Firefox, select to use SOCKS5 proxy: localhost:7070. This enables you access to Dropbox's homepage and download the Ubuntu package.
- Install the package by clicking it in Nautilus. To check the installation, in a shell, type the command
dropbox start -i
If you can see some error messages complaining network access restriction, you made it. - Add the following lines to /etc/tsocks.conf:
server = 127.0.0.1
If you are using proxychains, you need to modify /etc/proxychains.conf or make your own ~/.proxychains.conf.
server_type = 5
server_port = 7070 - This time, using tsocks to launch the Dropbox online install procedure:
tsocks dropbox start -i
Cross your fingers and wait for it to download and install Dropbox, until you see Dropbox icon appears on the top-right corner of your screen. - Right-click Dropbox icon, select "Preferences", and set SOCKS5 proxy like you did for Firefox. Hopefully, Dropbox starts to sync files you need now.
Good luck!
Jun 4, 2010
Building Distributed Programs Using GCC
In the case of distributed computing, a program is build (into a binary) and distributed on multiple computers for running. It is often that we do not want to install libraries depended by our program on every working computers. Instead, we can instruct GCC to link static libraries by setting the environment variable:
I have tried this method under Cygwin and Ubuntu Linux. However, if I do this under Darwin (Mac OS X 10.6 Snow Leopard), the linker complains that
LDFLAGS=-static -static-libgcc
I have tried this method under Cygwin and Ubuntu Linux. However, if I do this under Darwin (Mac OS X 10.6 Snow Leopard), the linker complains that
ld: library not found for -lcrt0.oIn this Technical Q&A, Apple explains that they want to make Mac OS X upgrading easier, so they do not provide crt0.o to encourage dynamic linking.
Jun 3, 2010
Uint64 Constants
If we write uint64 a = 0xffffffffffffffff;, the compiler often complains:
error: integer constant is too large for ‘long’ typeWhat we need is to add the LLU suffix: uint64 a = 0xffffffffffffffffLLU;
Jun 2, 2010
Launch a Series of Hadoop Pipes Task
It is OK to call runTask multiple times from within main() in a Hadoop Pipes program to launch a series of MapReduce tasks. However, one thing to remember: MapReduce tasks must not have conflicts output directory, because Hadoop runtime does not start a MapReduce task whose output directory exists.
Incremental Parsing Using Boost Program Options Library
I have to say I fell in love with boost::program_options since the first time I use it in developing my own C++ MapReduce implementation. It can parse command line parameters as well as configuration files. This makes it convenient for programs which supports and expects a bunch of options, where a MapReduce program is a typical example.
A special use-case of a command line parser is that a function need to parse some options out from the command line parameters, and then the rest parameters are passed to another function, which parse other options. For example, the MapReduce runtime requires to get options like "num_map_workers", "num_reduce_workers", etc, and the rest of the program (user customized map and reduce functions) need to parse application-specific options like "topic_dirichlet_prior", "num_lda_topics", etc. boost::program_options supports such kind of multi-round parsing, where the key is boost::program_options::allow_unregistered(). Here attaches a sample program: (For more explanation on this program, please refer to the official document of boost::program_options.)
Finally I have to tell that early boost version (e.g., 1.33.1 packed in Cygwin) has bugs in program_options, which leads to core dump in case of unknown options. The solution to download and build your own boost libraries. I just built 1.43.0 on Cygwin on my Windows computer.
A special use-case of a command line parser is that a function need to parse some options out from the command line parameters, and then the rest parameters are passed to another function, which parse other options. For example, the MapReduce runtime requires to get options like "num_map_workers", "num_reduce_workers", etc, and the rest of the program (user customized map and reduce functions) need to parse application-specific options like "topic_dirichlet_prior", "num_lda_topics", etc. boost::program_options supports such kind of multi-round parsing, where the key is boost::program_options::allow_unregistered(). Here attaches a sample program: (For more explanation on this program, please refer to the official document of boost::program_options.)
#include <iostream>
#include <string>
#include <vector>
#include <boost/program_options/option.hpp>
#include <boost/program_options/options_description.hpp>
#include <boost/program_options/variables_map.hpp>
#include <boost/program_options/parsers.hpp>
using namespace std;
namespace po = boost::program_options;
int g_num_map_workers;
int g_num_reduce_workers;
vector<string> foo(int argc, char** argv) {
po::options_description desc("Supported options");
desc.add_options()
("num_map_workers", po::value<int>(&g_num_map_workers), "# map workers")
("num_reduce_workers", po::value<int>(&g_num_reduce_workers), "# reduce workers")
;
po::variables_map vm;
po::parsed_options parsed =
po::command_line_parser(argc, argv).options(desc).allow_unregistered().run();
po::store(parsed, vm);
po::notify(vm);
cout << "The following options were parsed by foo:\n";
if (vm.count("num_map_workers")) {
cout << "num_map_workers = " << g_num_map_workers << "\n";
}
if (vm.count("num_reduce_workers")) {
cout << "num_reduce_workers = " << g_num_reduce_workers << "\n";
}
return po::collect_unrecognized(parsed.options, po::include_positional);
}
void bar(vector<string>& rest_args) {
po::options_description desc("Supported options");
desc.add_options()
("apple", po::value<int>(), "# apples")
;
po::variables_map vm;
po::parsed_options parsed =
po::command_line_parser(rest_args).options(desc).allow_unregistered().run();
po::store(parsed, vm);
po::notify(vm);
cout << "The following options were parsed by bar:\n";
if (vm.count("apple")) {
cout << "apple = " << vm["apple"].as<int>() << "\n";
}
}
int main(int argc, char** argv) {
vector<string> rest_options = foo(argc, argv);
cout << "The following cmd args cannot not be recognized by foo:\n";
for (int i = 0; i < rest_options.size(); ++i) {
cout << rest_options[i] << "\n";
}
bar(rest_options);
}
Finally I have to tell that early boost version (e.g., 1.33.1 packed in Cygwin) has bugs in program_options, which leads to core dump in case of unknown options. The solution to download and build your own boost libraries. I just built 1.43.0 on Cygwin on my Windows computer.
May 23, 2010
The Efficiency of AWK Associative Array
I did a little experiment comparing C++ STL map with AWK associative array in counting word frequency of large text files. The result is astonishing: AWK associative array is about 6 times faster than the C++ code!
At first, I put my eyes on the C++ code that splits a line into words. I tried STL istringstream, C strtok_r, and a string splitting trick that I learned in Google. However, these choices do not affect the efficiency saliently.
Then I realized the lesson I learned from parallel LDA (a machine learning method, which has been a key part of my research for over three years) --- map is about 10 times slower than map. I found that this issue has been thoroughly explained by Lev Kochubeevsky, principle engineer at Netscape, in 2003. Unfortunately, seems no improvement to STL string emerged since then.
On the other hand, I highly suspect that AWK, an interpreted language, implements a trie-based data structure for maps with string-keys.
At first, I put my eyes on the C++ code that splits a line into words. I tried STL istringstream, C strtok_r, and a string splitting trick that I learned in Google. However, these choices do not affect the efficiency saliently.
Then I realized the lesson I learned from parallel LDA (a machine learning method, which has been a key part of my research for over three years) --- map
On the other hand, I highly suspect that AWK, an interpreted language, implements a trie-based data structure for maps with string-keys.
SSHFS, Poor Guys' Network File-system
SSHFS is good: as long as one has SSH access, he can mount remote directories, even if he does not have administrative accesses required by traditional network filesystems like NFS or Samba.
May 22, 2010
Install and Configure MPICH2 on Ubuntu
The general procedure is described in
http://developer.amd.com/documentation/articles/pages/HPCHighPerformanceLinpack.aspx#four
I have encountered two cases where MPD on multiple nodes cannot communicate with each other:
sudo iptables -P INPUT ACCEPT
sudo iptables -P OUTPUT ACCEPT
sudo ufw disable
For 2., I just re-edit /etc/hosts to ensure all nodes are referred by their real IP addresses, instead of loop-back style addresses.
http://developer.amd.com/documentation/articles/pages/HPCHighPerformanceLinpack.aspx#four
I have encountered two cases where MPD on multiple nodes cannot communicate with each other:
- The firewall prevents such communication, and
- There are ambiguity in /etc/hosts.
sudo iptables -P INPUT ACCEPT
sudo iptables -P OUTPUT ACCEPT
sudo ufw disable
For 2., I just re-edit /etc/hosts to ensure all nodes are referred by their real IP addresses, instead of loop-back style addresses.
May 18, 2010
Hadoop Pipes Is Incompatible with Protocol Buffers
I just found another reason that I do not like Hadoop Pipes --- I cannot use a serialization of Google protocol buffer as map output key or value.
For those who are scratching your heads for weird bugs from your Hadoop Pipes programs using Google protocol buffers, please have a look at the following sample program:
The reducer outputs the size of the map output values, which contains special characters: new-line, null-term and tab. If Hadoop Pipes allows such special characters, then we should see reduce outputs 26, the length of string
However, unfortunately, we see 12 in the output, which is the length of string
For those who are scratching your heads for weird bugs from your Hadoop Pipes programs using Google protocol buffers, please have a look at the following sample program:
#include <string>
#include <hadoop/Pipes.hh>
#include <hadoop/TemplateFactory.hh>
#include <hadoop/StringUtils.hh>
using namespace std;
class LearnMapOutputMapper: public HadoopPipes::Mapper {
public:
LearnMapOutputMapper(HadoopPipes::TaskContext& context){}
void map(HadoopPipes::MapContext& context) {
context.emit("", "apple\norange\0banana\tpapaya");
}
};
class LearnMapOutputReducer: public HadoopPipes::Reducer {
public:
LearnMapOutputReducer(HadoopPipes::TaskContext& context){}
void reduce(HadoopPipes::ReduceContext& context) {
while (context.nextValue()) {
string value = context.getInputValue(); // Copy content
context.emit(context.getInputKey(), HadoopUtils::toString(value.size()));
}
}
};
int main(int argc, char *argv[]) {
return HadoopPipes::runTask(HadoopPipes::TemplateFactory<LearnMapOutputMapper,
LearnMapOutputReducer>());
}
The reducer outputs the size of the map output values, which contains special characters: new-line, null-term and tab. If Hadoop Pipes allows such special characters, then we should see reduce outputs 26, the length of string
"apple\norange\0banana\tpapaya".
However, unfortunately, we see 12 in the output, which is the length of string
"apple\norange"
This shows that map outputs in Hadoop Pipes cannot contain the null-term character, which, however, may appear in a serialization of protocol buffer, as explained in the protocol buffers encoding scheme at:
http://code.google.com/apis/protocolbuffers/docs/encoding.html
I hate Hadoop Pipes, a totally incomplete but released MapReduce API.
I hate Hadoop Pipes, a totally incomplete but released MapReduce API.
May 16, 2010
MPI-based MapReduce Implementation
离开Google之后就没有那么好用的MapReduce实现了。在拼命寻找替代品的时候,发现已经有人在用 MPI 实现 MapReduce。一个 open source 实现是:
http://www.sandia.gov/~sjplimp/mapreduce/doc/Manual.html
下载之后用了一下,发现对 MapReduce API 的封装很不到位。因此编程方法根本不是在Google 使用 MapReduce 时候的那一套。相比较而言,Hadoop Pipes 对 MapReduce API 的封装更便于使用。
这就牵扯到一个问题:MapReduce 到底强在哪儿?为什么用过 Google MapReduce 的人都会喜欢它?
MapReduce 的很多优势在论文里和论坛里都有人强调过了 —— 它可以处理海量的数据,可以支持 auto fault-recovery。但是我觉得最重要的一点是 MapReduce 的 API 很简单 —— 它容许程序员通过定义一个 map 函数和一个 reduce 函数就搞定一个并行程序。所有的 distributed IO、communications、task synchronization、load balancing、fault recovery都不用用户操心。
很多人在骂 Hadoop 慢。作为一个 Java implementation,Hadoop 确实是我见过的诸多 MapReduce 实现中最慢的(实际使用起来往往比 Last.fm 的 Bash MapReduce 还要慢),但是用Hadoop的人很多。难不成原因之一就是 API 好用?
我的感觉是:如果一个 MapReduce implementation 失去了 MapReduce 给程序员带来的便利,它的其他各种优势恐怕都要大打折扣了。(离开Google一个多月,我已经记不得我写过哪些不是用 MapReduce 的程序了。)
BTW:说到这里,顺便说一下, Sphere/Sector (http://sector.sourceforge.net/doc.html) 的 API 也不是 MapReduce API 。从 Sphere Sector 的 tutorial slides 里贴一下一个demo program:
http://www.sandia.gov/~sjplimp/mapreduce/doc/Manual.html
下载之后用了一下,发现对 MapReduce API 的封装很不到位。因此编程方法根本不是在Google 使用 MapReduce 时候的那一套。相比较而言,Hadoop Pipes 对 MapReduce API 的封装更便于使用。
这就牵扯到一个问题:MapReduce 到底强在哪儿?为什么用过 Google MapReduce 的人都会喜欢它?
MapReduce 的很多优势在论文里和论坛里都有人强调过了 —— 它可以处理海量的数据,可以支持 auto fault-recovery。但是我觉得最重要的一点是 MapReduce 的 API 很简单 —— 它容许程序员通过定义一个 map 函数和一个 reduce 函数就搞定一个并行程序。所有的 distributed IO、communications、task synchronization、load balancing、fault recovery都不用用户操心。
很多人在骂 Hadoop 慢。作为一个 Java implementation,Hadoop 确实是我见过的诸多 MapReduce 实现中最慢的(实际使用起来往往比 Last.fm 的 Bash MapReduce 还要慢),但是用Hadoop的人很多。难不成原因之一就是 API 好用?
我的感觉是:如果一个 MapReduce implementation 失去了 MapReduce 给程序员带来的便利,它的其他各种优势恐怕都要大打折扣了。(离开Google一个多月,我已经记不得我写过哪些不是用 MapReduce 的程序了。)
BTW:说到这里,顺便说一下, Sphere/Sector (http://sector.sourceforge.net/doc.html) 的 API 也不是 MapReduce API 。从 Sphere Sector 的 tutorial slides 里贴一下一个demo program:
可以看到各种initialization、finalization、operator-loading 之类的操作都是需要用户来写的。其实把这些封装成 MapReduce API 并没有技术难度。而封装一下可以给用户省去很多麻烦。Sector::init(); Sector::login(…)
SphereStream input;
SphereStream output;
SphereProcess myProc;
myProc.loadOperator(“func.so”);
myProc.run(input, output, func, 0);
myProc.read(result)
myProc.close();
Sector::logout(); Sector::close();
Apr 19, 2010
Running Hadoop on Mac OS X (Single Node)
I installed Hadoop, built its C++ components, and built and ran Pipes programs on my iMac running Snow Leopard.
Installation and Configuration
Basically, I followed Michael G. Noll's guide, Running Hadoop On Ubuntu Linux (Single-Node Cluster), with two things different from the guide.
In Mac OS X, we need to choose to use Sun's JVM. This can be done using System Preference. Then In both .bash_profile and $HADOOP_HOME/conf/hadoop-env.sh, set the JAVA_HOME environment variable:
export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home
I did not create special account for running Hadoop. (I should, for security reasons, but I am lazy and my iMac is only for personal development, but not real computing...) So, I need to chmod a+rwx /tmp/hadoop-yiwang, where yiwang is my account name, as well what ${user.name} refers to in core-site.xml.
After finishing installation and configuration, we should be able to start all Hadoop services, build and run Hadoop Java programs, and monitor their activities.
Building C++ Components
Because I do nothing about Java, I write Hadoop programs using Pipes. The following steps build Pipes C++ library in Mac OS X:
Build and Run Pipes Programs
The following command shows how to link to Pipes libraries:
Build libHDFS
There are some bugs in libHDFS of Apache Hadoop 0.20.2, but it is easy to fix them:
Installation and Configuration
Basically, I followed Michael G. Noll's guide, Running Hadoop On Ubuntu Linux (Single-Node Cluster), with two things different from the guide.
In Mac OS X, we need to choose to use Sun's JVM. This can be done using System Preference. Then In both .bash_profile and $HADOOP_HOME/conf/hadoop-env.sh, set the JAVA_HOME environment variable:
export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home
I did not create special account for running Hadoop. (I should, for security reasons, but I am lazy and my iMac is only for personal development, but not real computing...) So, I need to chmod a+rwx /tmp/hadoop-yiwang, where yiwang is my account name, as well what ${user.name} refers to in core-site.xml.
After finishing installation and configuration, we should be able to start all Hadoop services, build and run Hadoop Java programs, and monitor their activities.
Building C++ Components
Because I do nothing about Java, I write Hadoop programs using Pipes. The following steps build Pipes C++ library in Mac OS X:
- Install XCode and open a terminal window
- cd $HADOOP_HOME/src/c++/utils
- ./configure
- make install
- cd $HADOOP_HOME/src/c++/pipes
- ./configure
- make install
Build and Run Pipes Programs
The following command shows how to link to Pipes libraries:
g++ -o wordcount wordcount.cc \To run the program, we need a configuration file, as shown by Apache Hadoop Wiki page.
-I${HADOOP_HOME}/src/c++/install/include \
-L${HADOOP_HOME}/src/c++/install/lib \
-lhadooputils -lhadooppipes -lpthread
Build libHDFS
There are some bugs in libHDFS of Apache Hadoop 0.20.2, but it is easy to fix them:
cd hadoop-0.20.2/src/c++/libhdfsSince Mac OS X uses DYLD to mange shared libraries, you need to specify the directory holding libhdfs.so using environment variable DYLD_LIBRARY_PATH. (LD_LIBRARY_PATH does not work.):
./configure
Remove #include "error.h" from hdfsJniHelper.c
Remove -Dsize_t=unsigned int from Makefile
make
cp hdfs.h ../install/include/hadoop
cp libhdfs.so ../install/lib
export DYLD_LIBRARY_PATH=$HADOOP_HOME/src/c++/install/lib:$DYLD_LIBRARY_PATHYou might want to add above line into your shell configure file (e.g., ~/.bash_profile).
Apr 11, 2010
Get Through GFW on Mac OS X Using IPv6
In my previous post, I explained how to get through the GFW on Mac OS X using Tor. Unfortunately, it seems that Tor has been banned by GFW in recently months. However, some blog posts and mailing list claims that GFW has not been able to filter IPv6 packets. So I resorted to the IPv6 tunneling protocol, Teredo. A well known software implementation of Teredo on Linux and BSD is Miredo. Thanks to darco, who recently ported Miredo to Mac OS X, in particular, 10.4, 10.5 and 10.6 with 32-bit kernel. You can drop by darco's Miredo for Mac OS X page or just download the universal installer directly. After download, click to install, and IPv6 tunneling via IPv4 is setup on your Mac.
Before you can use IPv6 to get through the GFW, you need to know IPv6 addresses of the sites you want to visit. You must add these addresses into your /etc/hosts file, so the Web browser has no need to resolve the addresses via IPv4 (which is under monitoring by GFW). This Google Doc contains IPv6 addresses to most Google services (including Youtube).
Mar 27, 2010
Customizing Mac OS X 10.6 For a Linux User
I have been a Linux user for years, and changed to Mac OS X 10.6 Snow Leopard in recent months. Here follows things I've done for Snow Leopard to make it suit for my work habits.
- Emacs.
I prefer Aquamacs version 20.1preview5 than the stable version 19.x when I wrote this post. Aquamacs has many useful Emacs plugins packed already, including AUCTeX for LaTeX editing. - PdfTk.
Under Unix, Emacs/AUCTeX invokes pdf2dsc (a component in the pdftk package) to do inline preview in PDFLaTeX mode. Under Mac OS X, thanks to Frédéric Wenzel, who created a DMG of PdfTk for us. - LaTeX/PDF Preview.
There is a free PDF viewer, Skim, under Mac OS X, which works like the ActiveDVI Viewer under Linux, but displays PDF files instead of DVI. Whenever you edit your LaTeX source and recompile, Skim will update automatically what it is displaying. - Terminal.
As many others, I use iTerm. To support bash shortcut keys like Alt-f/b/d, you need to customize iTerm as suggested by many Google search results. In particular, remember to select "High interception priority" when you do such customization for iTerm under Snow Leopard.
Chrome 的安全机制
今天看到多篇新闻报道:在 Pwn2Own 2010 黑客大赛上,针对各种浏览器的攻击中,只有 Google Chrome 屹立不倒。随便 Google 一下,会发现很多黑客把 Chrome 的安全性归结于 Chrome 的 sandbox(沙箱)机制。我因此好奇的看了看 Chromium(Google Chrome 的 open source project)的文档,
大概了解了一下 Chrome sandbox 的基本原理。
Chrome 会启动两类进程:target 和 broker:
- Target 进程执行那些容易被黑客影响并做坏事的工作;主要包括(1)Javascript 程序的解释,和(2)HTML rendering。Target 进程是由 broker 进程创建的。创建之初,broker 就把 target 进程的各种访问权限都剥夺了。也就是说虽然 target 进程可以像所有用户态进程那样通过操作系统调用,请操作系统内核做事,但是操作系统内核会认为 target 进程没有权限,因而拒绝之。【注:在现代操作系统中,用户进程对任何系统资源的访问都得通过“请操作系统内核帮忙”来完成。】所以 target 实际上只能通过进程间调用,请 broker 进程来帮忙做事。
- Broker 进程扮演着操作系统内核的角色 —— 因为 broker 进程执行的代码是浏览器的作者写的,并且不易被坏人注入坏代码,所以我们可以依赖它检查 target 进程请它做的事情是不是靠谱。如果不靠谱,则拒绝之。
简单的说,Chrome 的 sandbox 机制复制了操作系统的两层安全概念 —— 用户进程(target 进程)没实权,实权由操作系统内核(broker 进程)把持。实际上是装了第二把锁 —— 当用户和第三方软件对操作系统的错误配置导致操作系统安全机制失效的时候,第二把锁的作用就显示出来了。
Mar 26, 2010
Data-Intensive Text Processing with MapReduce
A book draft, Data-Intensive Text Processing with MapReduce, on parallel text algorithms with MapReduce can be found here. This book has chapters covering graph algorithms (breath-first traversal and PageRank) and learning HMM using EM. The authors work great on presenting concepts using figures, which are comprehensive and intuitive.
Indeed, there are many other interesting stuff you can put into a book on MapReducing text processing algorithms. For example, parallel latent topic models like latent Dirichlet allocation, and tree pruning/learning algorithms for various purposes.
Stochastic Gradient Tree Boosting
The basic idea of boosting as functional gradient descent and stages/steps as trees, known by gradient boosting, is presented by a Stanford paper:
- Jerome Friedman. Greedy Function Approximation: A Gradient Boosting Machine. The Annuals of Statistics. 2001
- Jerome Friedman. Stochastic Gradient Boosting. 1999.
- PLANET: Massively Parallel Learning of Tree Ensembles with MapReduce. VLDB 2009
- Stochastic Gradient Boosted Distributed Decision Trees. CIKM 2009
Mar 24, 2010
Fwd: Ten Commands Every Linux Developer Should Know
I like this article in Linux Journal, which reveals some very useful Linux commands that I have never used in my years experience with Unix's.
Mar 15, 2010
Some Interesting Data Sets
- The ArXiv data set, including full text, abstract/title and citations:
http://www.cs.cornell.edu/projects/kddcup/datasets.html - The CiteSeer dataset, including Dublin core standard fields and citations:
http://citeseer.ist.psu.edu/oai.html
Feb 27, 2010
Could Latent Dirichlet Allocation Hanlde Documents with Various Length?
I heart some of my colleagues who are working on another latent topic model, which is different from LDA, complains that LDA like documents with similar lengths. I agree with this. But I feel that can be fixed easily. Here follows what I think.
The Gibbs sampling algorithm of LDA samples latent topic assignments from as follows
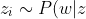P(z|d) \propto \frac{N(w,z) + \beta}{N(z) + V\beta} \frac{N(z,d) + \alpha}{L_d + \alpha} "z_i \sim P(w|z)P(z|d) \propto \frac{N(w,z) + \beta}{N(z) + V\beta} \frac{N(z,d) + \alpha}{L_d + \alpha}")
where V is the vocabulary size and Ld is the length of document d.
The second term is dependent with the document length. Just consider an example document is about two topics, A, and B, and half of its words are assigned topic A, the other half are assigned topic B. So the P(z|d) distribution should have two high bins (height proportional to L/2 + alpha), and all elsewhere are short bins (height proportional to alpha). So, you see, if the document has 1000 words, alpha has trivial effect to the shape of P(z|d); but if the document contains only 2 words, alpha would have more effects on building the shape of P(z|d).
An intuitive solution to above problem is to use small alpha for short document (and vice versa). But would this break the math assumptions under LDA? No. Because this is equivalent to use different symmetric Dirichlet prior on documents with different lengths. This does not break the Dirichlet-multinomial conjugacy required by LDA's Gibbs sampling algorithm, but just express a little more prior knowledge than using a symmetric prior for all documents. Let us set

for each document. And users need to specify parameter k as they need to specify alpha before.
The Gibbs sampling algorithm of LDA samples latent topic assignments from as follows
where V is the vocabulary size and Ld is the length of document d.
The second term is dependent with the document length. Just consider an example document is about two topics, A, and B, and half of its words are assigned topic A, the other half are assigned topic B. So the P(z|d) distribution should have two high bins (height proportional to L/2 + alpha), and all elsewhere are short bins (height proportional to alpha). So, you see, if the document has 1000 words, alpha has trivial effect to the shape of P(z|d); but if the document contains only 2 words, alpha would have more effects on building the shape of P(z|d).
An intuitive solution to above problem is to use small alpha for short document (and vice versa). But would this break the math assumptions under LDA? No. Because this is equivalent to use different symmetric Dirichlet prior on documents with different lengths. This does not break the Dirichlet-multinomial conjugacy required by LDA's Gibbs sampling algorithm, but just express a little more prior knowledge than using a symmetric prior for all documents. Let us set
for each document. And users need to specify parameter k as they need to specify alpha before.
Feb 21, 2010
S-shaped Functions
The logit (logistic sigmoid) function:
 = \frac{1}{1 + \exp(-x)}")
The tanh function:
 = 2\sigma(x) - 1")
The probit function:
 = \int_{-\infty}^x \mathcal{N}(\theta;0,1) \;\mathrm{d}\theta")
where
 \approx \sigma(x)")
For more on this approximation, look at Figure 4.9 of Pattern Recognition and Machine Learning.
The tanh function:
The probit function:
where
For more on this approximation, look at Figure 4.9 of Pattern Recognition and Machine Learning.
Feb 20, 2010
Cavendish Experiment and Modern Machine Learning
This is just a joke, so do not follow it seriously...
The very usual case in modern machine learning is as follows:
However, this is a joke as I said so you cannot use it in your lecture notes on machine learning. The fact was that Cavendish did not measure G as stated in many textbooks. Instead, he measures the earth directly by comparing (1) the force that a big ball with known mass attracts a small ball with (2) the force that the earth attracts the small ball. If the ratio (2)/(1) is N, then the earth is N times weight of the big ball.
The very usual case in modern machine learning is as follows:
- design a model to describe the data, for example, suppose some kind of 2D points are generated along a quadratic curve y = a*x^2 + b*x + c, and
- design an algorithm that estimates the model parameters, in our case, a, b, and c, given a set of data (observations), x_1,y_1,x_2,y_2,...x_n,y_n.
- The model parameters can be used in some way, say, given a new x and predict its corresponding y.
F = G * m1 * m2 / r^2And, using the estimated model parameter G, we can do somethings interesting. For example, measure the weight of the earth (by measuring the weight/gravity F of a known small ball m1, and put them back into the equation to get m2, the mass of earth).
However, this is a joke as I said so you cannot use it in your lecture notes on machine learning. The fact was that Cavendish did not measure G as stated in many textbooks. Instead, he measures the earth directly by comparing (1) the force that a big ball with known mass attracts a small ball with (2) the force that the earth attracts the small ball. If the ratio (2)/(1) is N, then the earth is N times weight of the big ball.
Feb 14, 2010
Highlights in LaTeX
To make part of the text highlighted in LaTeX, use the following two packages
\usepackage{color}
\usepackage{soul}
And in the text, use macro \hl:The authors use \hl{$x=100$ in their demonstration}.
Note that if you use only soul without color, \hl just fails to underlines.
Feb 4, 2010
Google Puts New Focus on Outside Research
It is recently reported that Google is stepping up its funding to support the research following four areas:
- machine learning
- the use of cellphones as data collection devices in science
- energy efficiency
- privacy
Feb 3, 2010
Reduce Data Correlation by Recenter and Rescale
In the MATLAB statistics demo document, the training data (a set of car weights) are recentered and rescaled as follows:
% A set of car weightsAnd the document explains the reason of recenter and rescale as
weight = [2100 2300 2500 2700 2900 3100 3300 3500 3700 3900 4100 4300]';
weight = (weight-2800)/1000; % recenter and rescale
The data include observations of weight, number of cars tested, and number failed. We will work with a transformed version of the weights to reduce the correlation in our estimates of the regression parameters.Could anyone tell me why the recenter and rescale can reduce the correlation?
Feb 2, 2010
Making Videos Playable on Android and iPhone
You might want to convert you home-made video (no pirated video :-!) into a format that your Android phone can play. The video formats that Android support are listed in Android developers' site:
Among the listed formats, H.264 (as a realization of the MPEG-4 standard) has been well accepted by the industry. Companies including Apple has switched to it. In the following, I will show you that using open source software on a Linux box can convert your video into H.264 with AVC video and AAC audio. I took the following post as a reference, but with updates.
First of all, you need to install the following software packages:
- mplayer: a multimedia player
- mencoder: MPlayers's movie encoder
- faac: an AAC audio encoder
- gpac: a small and flexible implementaiton of the MPEG-4 system standard
- x264: video encoder for the H.264/MPEG-4 AVC standard
Then we do the following steps to convert the video.avi into a .mp4 file in H.264 format.
- Extract the audio information from video.avi using MPlayer:
mplayer -ao pcm -vc null -vo null video.avi
This will generate a audiodump.wav file. - Encode audiodump.wav into AAC format
faac --mpeg-vers 4 audiodump.wav
This generates a audiodump.aac file. - Use mencoder to convert the video content of video.avi into YUV 4:2:0 format, and use x264 to encode the output into AVC format
mkfifo tmp.fifo.yuv
We created a named pipe to buffer between mencoder and x264. These command lines generate both Quicktime-compatible and H.264-compatible content. This is because Apple Quicktime can now hold H.264 content. Be aware to specify the same video size to mencoder and x264. In above example, the size is 800x450.
mencoder -vf scale=800:450,format=i420 \
-nosound -ovc raw -of rawvideo \
-ofps 23.976 -o tmp.fifo.yuv video.mp4 2>&1 > /dev/null &
x264 -o max-video.mp4 --fps 23.976 --bframes 2 \
--progress --crf 26 --subme 6 \
--analyse p8x8,b8x8,i4x4,p4x4 \
--no-psnr tmp.fifo.yuv 800x450
rm tmp.fifo.yuv - Merge the AAC audio and AVC video into a .mp4 file using gpac
MP4Box -add max-video.mp4 -add audiodump.aac \
MP4Box is a tool in the gpac package.
-fps 23.976 max-x264.mp4
如何在Mac OS X上配置一个Web服务器
最近在我的imac上配置了一个Web服务器,用于管理我自己的技术笔记。和很多朋友们一样,我的机器通过连接ADSL的无线路由器上网,所以遇到的问题应该比较典型,因此我把配置流程记录下来,和大家共享。
 现在可以在Web浏览器的地址栏里输入http://localhost/~wangyi访问到自己的主页了。【注意wangyi是我在我的imac上的用户名,你得使用你自己的用户名取代它。】这个页面对应的HTML文件就是/Users/wangyi/Sites/index.html。可以通过编辑它来定制你自己的主页。
现在可以在Web浏览器的地址栏里输入http://localhost/~wangyi访问到自己的主页了。【注意wangyi是我在我的imac上的用户名,你得使用你自己的用户名取代它。】这个页面对应的HTML文件就是/Users/wangyi/Sites/index.html。可以通过编辑它来定制你自己的主页。
我使用的是TP-LINK的TL-WR541G+无线路由器。为了访问它的配置界面,只需要在浏览器里输入http://192.168.1.1。【192.168.1.1是我的无线路由器的内部IP地址;我的imac的内部IP地址是192.168.1.100。这些是TP-LINK无线路由器的默认设置。】如下图所示: 通过在“转发规则”的“虚拟应用程序”项目中,把“触发端口”和“开放端口”都设置成80(HTTP协议的标准端口号),Internet用户就可以在浏览器里输入我的外部IP来访问我的Web服务了。
通过在“转发规则”的“虚拟应用程序”项目中,把“触发端口”和“开放端口”都设置成80(HTTP协议的标准端口号),Internet用户就可以在浏览器里输入我的外部IP来访问我的Web服务了。
但是现在的问题是,大家通常不知道我的外部IP,因为这是我的ISP(中国电信)分配给我的无线路由器的。但是没问题,我知道我的外部IP,所以我只要注册一个域名指向我的外部IP,然后向大家公开我的域名就可以了。
通常来说,注册域名都是要花钱的。国内只有一家叫做3322.org的公司提供免费域名注册服务。为了图个便宜,我就用3322.org了。为此,需要访问www.3322.org:
很多系统(包括Mac OS X)没有自带lynx,但是附带了一个更简单的标准程序叫curl。用curl向3322.org汇报IP地址的命令行是:
其中,~/.emacs.d/lisp/muse是我的Muse的安装目录。~/TechNotes是存储我的技术文档的目录。我的每一篇技术文档是这个目录下的一个后缀为.muse的文本文件(比如HowToSetup.muse)。当我用Emacs编辑这个文件时,只要按组合键control-c control-p,Emacs Muse就自动将这个文档输出成HTML格式,存放在~/Sites/TechNotes目录下(HowToSetup.html)。
启动Mac OS X上的Apache
Mac OS X自带了Apache。要启动它很容易。如下图所示:启动System Preference,在Internet & Wireless类别里选择Sharing。然后勾上Web Sharing。这样Apache就启动了。让大家能访问我的主页
我家是通过电信的ADSL服务上网的。为了让家里的几台电脑都能上网,我在ADSL modem上接了一个无线路由器。这样,家里的电脑启动的时候,是由无线路由器动态分配IP地址。而无线路由器的外部IP地址是电信通过ADSL服务给分配的。为了让Internet上的用户都能通过我的外部IP访问到我的Web服务,我需要在无线路由器上做一些设置【端口转发,port forwarding】,使得无线路由器能把Internet用户的访问请求转发到我的imac电脑的Web服务器程序。我使用的是TP-LINK的TL-WR541G+无线路由器。为了访问它的配置界面,只需要在浏览器里输入http://192.168.1.1。【192.168.1.1是我的无线路由器的内部IP地址;我的imac的内部IP地址是192.168.1.100。这些是TP-LINK无线路由器的默认设置。】如下图所示:
设置域名
但是现在的问题是,大家通常不知道我的外部IP,因为这是我的ISP(中国电信)分配给我的无线路由器的。但是没问题,我知道我的外部IP,所以我只要注册一个域名指向我的外部IP,然后向大家公开我的域名就可以了。
通常来说,注册域名都是要花钱的。国内只有一家叫做3322.org的公司提供免费域名注册服务。为了图个便宜,我就用3322.org了。为此,需要访问www.3322.org:
- 在www.3322.org的首页上,免费注册一个用户。我的用户名是cxwangyi
- 到“我的控制台”页面,在“动态域名”一栏下,点击“新建”。然后选择一个域名后缀。3322.org提供了几个选择。我选了7766.org。我的域名是我在3322.org的用户名加上我选择的域名后缀,也就是cxwangyi.7766.org。这个配置页面能自动检测我们的外部IP地址,所以不用我们手工输入。其他选项也都选择默认值就行了。抓图如下:
更新外部IP地址
绝大多数ISP(包括中国电信)使用DHCP协议分配IP地址。这就意味着每隔一段时间,我们的IP地址就变了。所以上一步中和cxwangyi.7766.org绑定的IP地址,过了一段时间之后可能就分配给别人的机器了。为此,我们需要时不时的通知3322.org,报告我们最新的IP地址。一个笨办法是每隔一段时间时间访问上图中的设置界面,手工更新我们的IP地址。一个聪明一些的办法是下载3322.org客户端程序,它在运行期间,会自动向3322.org汇报我们的IP地址。第三个办法是用一些标准的工具程序,访问3322.org预留的一个URL,这样我们的IP地址就自然的随着HTTP协议,发给了3322.org,并且被记录下来。3322.org的页面上建议大家使用lynx;对应的命令行是:lynx -mime_header -auth=cxwangyi:123456 \其中cxwangyi是我在3322.org上注册的用户名,123456是对应的口令。cxwangyi.7766.org是上一步里我们在3322.org上注册的域名。这些你都得用你自己的。
"http://www.3322.org/dyndns/update?system=dyndns&hostname=cxwangyi.7766.org"
很多系统(包括Mac OS X)没有自带lynx,但是附带了一个更简单的标准程序叫curl。用curl向3322.org汇报IP地址的命令行是:
curl -u cxwangyi:123456 \"http://www.3322.org/dyndns/update?system=dyndns&hostname=cxwangyi.7766.org"利用curl或者lynx,以下这个非常简单的Bash脚本每隔10秒钟,就向3322.org汇报一次当时的IP地址:
while [ true ]; \
sleep 10000; \
curl -u cxwangyi:123456 \
"http://www.3322.org/dyndns/update?system=dyndns&hostname=myhost.3322.org"; \
done
用Emacs Muse创建技术内容
有了Web服务,还得有内容。有无数的工具软件用于帮助制作网页。我用的是Emacs Muse,一个Emacs插件,允许用户用一种简单的wiki语法书写内容(包括插图甚至复杂的数学公式),并且可以把结果输出成HTML(或者PDF等格式)。Emacs Muse的下载和安装可以参考其主页上的说明。安装之后,我在我的.emacs文件里加入了如下设置:(add-to-list 'load-path "~/.emacs.d/lisp/muse")(require 'muse-mode) ; load authoring mode(require 'muse-html) ; load publishing styles I use(require 'muse-latex)(require 'muse-texinfo)(require 'muse-docbook)(require 'muse-latex2png) ; display LaTeX math equations(setq muse-latex2png-scale-factor 1.4) ; the scaling of equation images.(require 'muse-project) ; publish files in projects(muse-derive-style"technotes-html" "html":style-sheet "<link rel=\"stylesheet\" type=\"text/css\" media=\"all\" href=\"../css/wangyi.css\" />")(setq muse-project-alist'(("technotes" ("~/TechNotes" :default "index")(:base "technotes-html" :path "~/Sites/TechNotes"))))
Jan 20, 2010
Unix Philosophy
It had been a difficult problem to compare Windows and Linux. I had been holding the idea that in the Unix world, people write small and simple programs which work together via standard linkages like pipe and other inter-process communication mechanisms. However, under Windows, people tend to write a huge program which can do everything.
An example is word processing. In the Windows world, we have Microsoft Word, which has a huge number of functions: editing, rendering (WYSIWYG), spell checking, printing, and much more. However, in the Unix world, we use the TeX system, consisting of many programs, each does one simple thing -- TeX macro defines basic typesetting functions, LaTeX defines more, Emacs (or any other editor) edits, pdfLaTeX (and other converters) converts sources into PDF or other formats, AUCTeX or Lyx implements WYSIWYG, and etc.
Well, by mentioning above, I think I am not so bad as I see at least the Separation and Composition philosophy of the Unix world. However, there are many more that I have not been able to summarize. Anyway, the lucky thing is a master had summarized them for us, so, please refer to the great book The Art of Unix Programming.
Jan 19, 2010
Hierarchical Classification
A 2005 paper, Learning Classifiers Using Hierarchically Structured Class Taxonomies, discussed classification into a taxonomy. My general understand is that this problem can be solved by training a set of binary classifiers as the multi-label classification problem. More details delivered by this paper:
Types of Classification:
- Traditional: classify instances into mutually exclusive class labels,
- Multi-label: an instance may have more than one labels,
- Taxonomic: multi-label and labels are from a hierarchical taxonomy.
Solutions Proposed:
- Binarized: train a set of binary classifiers, each for a label in the taxonomy. In classification time, if an instance does not belongs to class C, then no need to check it with classifiers belonging to descendants of C.
- Split-based: need to read more to understand this solution.
From the experiment results, it seems that above two solutions have similar performance. And both differs from the bottom-up solution that I saw in Google.
Something New about LDA and HDP
The UC Irvin team have updated their work and published a JMLR 2009 paper: Distributed Algorithms for Topic Models. For HDP, they proposed a greedy approach to matching of new topics. I also like their ways to visualize the training process.
Diane Hu, a PhD student working on latent topic models for musical analysis, recently wrote a tutorial/survey on LDA, Latent Dirichlet Allocation for Text, Images, and Music, which introduced LDA basics as well its extension models for images and music.
SSH on Mac OS X
This article shows how to start an SSH server on Mac OS X, how to set up loginless, and how to tunnelling unsecure protocols over SSH.
The article explains how to change the port number of SSH on Mac OS X. Note that from Mac OS X 10.4, the mechanism for launching sshd changed from using xinetd to launchd, so changing the port number becomes a little harder.
The article explains how to change the port number of SSH on Mac OS X. Note that from Mac OS X 10.4, the mechanism for launching sshd changed from using xinetd to launchd, so changing the port number becomes a little harder.
Jan 18, 2010
Get Across GFW Using Tor and Bridges
在这个技术博客上,我很少用中文写文章。但是此文似乎只有中国用户需要看到。
作为一个中国网络用户,为了访问我的这个技术博客,我不得不翻墙。在我的iMac和MacBook Pro上,Tor是个很不错的工具。可惜最近不好用了。今晚稍微研究了一下,发现可以通过加入网桥来解决这个问题。
具体的做法是:
作为一个中国网络用户,为了访问我的这个技术博客,我不得不翻墙。在我的iMac和MacBook Pro上,Tor是个很不错的工具。可惜最近不好用了。今晚稍微研究了一下,发现可以通过加入网桥来解决这个问题。
具体的做法是:
- 给bridges@torproject.org写信,内容无所谓;稍后,对方会回复一封邮件,其中有几个可用的网桥。
- 在Vidalia的界面中选择Settings;在Settings对话框里切换到Network页;选中“My ISP blocks connections to the Tor network”;然后通过“Add a Bridge”输入框一条一条加入邮件中的网桥。可以参见以下抓图:


Jan 11, 2010
Jan 8, 2010
Generate Core Dump Files
If you want your program generates core dump files (including stack trace) when it encounters a segmentation fault, remember to set the following shell option
ulimit -c unlimitedBefore running your program.
Once the core file is generated (say core), we can check the stack trace using GDB:
Special Notes for Cygwin
gdb program_file coreThen type GDB command
wherewhich will show you the stack trace.
Special Notes for Cygwin
When a process (i.e. foo.exe) cores, a default stackdump foo.exe.stackdump is generated. This stackdump contains (among other things) stack frames and functions addresses. You can make some sense of it by using the `addr2line' utility, but it's not as convenient as using a debugger.
Which takes me to the actual useful bit on information in this post. You can instruct Cygwin to start your gdb debugger just in time when an fault occurs or have Cygwin generate a real core dump.
To achieve this, add `error_start=action' to the Cygwin environment variable:
# start gdb
export CYGWIN="$CYGWIN error_start=gdb -nw %1 %2"
# generate core dump
export CYGWIN="$CYGWIN error_start=dumper -d %1 %2"
A Step-by-Step Tutorial on Autotools
Autotools are so complicated for new users, however, I am lucky this evening and found an excellent step-by-step tutorial. By following it, I packed my Hadoop Streaming wrapper for C++ in few minutes! I would like to donate to the author if s/he wants. :-)
Jan 7, 2010
A C++ MapReduce "Implementation" Basing on Hadoop Streaming
Hadoop has two mechanisms to support using languages other than Java:
So, I would like to turn to use Streaming and C++. Michael G. Noll wrote an excellent tutorial on Streaming using Python, which shows that Streaming is equivalent to invoke your map and reduce program using the following shell command:
Of couse, as you know, Hadoop runs the shell pipes on a computing cluster in parallel.
Basing on Hadoop Streamming, I wrote a C++ MapReduce wrapper (more precisely, it should be called a MapReduce implementation, but the code is simple when built on Hadoop Streaming, that I feel embarrassed to call it an "implementation"). Anyway, I found it is interesting that this simple wrapper support secondary keys, whereas org.apache.hadoop.mapreduce does not yet. :-)
- Hadoop Pipes, which provides a C++ library pair to support Hadoop programs in C/C++ only, and
- Hadoop Streamining, which languages any executable files in map/reduce worker processes, and thus support any languages.
However, in Hadoop 0.20.1, the support to Pipes, known as Java code in package org.apache.hadoop.mapred.pipes have been marked deprecated. So I guess Hadoop 0.20.1 has not port to fully support Pipes. Some other posts in forums also discussed this issue.
cat input_file | map_program | sort | reduce_program
hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-0.20.1-streaming.jar \
-file ./word_count_mapper -mapper ./word_count_mapper \
-file ./word_count_reducer -reducer ./word_count_reducer \
-input ./input/*.txt -output
I have created a Google Code project to host this simple implementation: Hadoop Streaming MapReduce, and imported the code using the following command line:
svn import hadoop-streaming-mapreduce/ https://hadoop-stream-mapreduce.googlecode.com/svn/trunk -m 'Initial import'. So you should be able to checkout the code now.
Jan 6, 2010
Map-Reduce-Merge for Join Operation
In this SIGMOD 2007 paper: Map-reduce-merge: simplified relational data processing on large clusters, the authors add to Map-Reduce a Merge phase that can efficiently merge data already partitioned and sorted (or hashed) by map and reduce modules, and demonstrate that this new model can express relational algebra operators as well as implement several join algorithms.
However, I think the newly added merge stage could be implemented using another MapReduce job -- the mapper scans over key-value pairs of all lineage and output them identically; the shuffling stage will merge values of different lineage but the same key into reduce inputs; finally, the reducer can do whatever supposed to be done by merger.
Other people told me that there are more ways to do merge using MapReduce model. But above simple solution seems one of the most scalable. In short, if I am going to implement a parallel programming model given the objective to support joining of relational data, I would just implement MapReduce, rather than MapReduce-Merge.
Jan 2, 2010
Compare GNU GCJ with Sun's JVM
On this Wikipedia page, there is a link to Alex Ramos's experiment, which compares the performance of native binary generated by GNU's GCJ from Java program and bytecode binary generated by Sun's JDK and runs on JIT JVM. As Alex did the comparison on AMD CPU, I did more additional ones. Here are the results.
The first comparison was done by Alex; I just copy-n-pasted his results. The second was done on my workstation. The third on my IBM T60p notebook computer. I also tried to do the comparison on my MacBook Pro, but MacPorts cannot build and install GCJ correctly.
Generally, GCJ beats JIT on numerical computing. However, I have to mention that it takes a lot more time to start the binary generated by GCJ. (I do not know why...)
Here attaches the Java source code (VectorMultiplication.java), which is almost identical to Alex's, but use much shorter vectors (1M v.s. 20M), so more computer can run it.
| System | Java version | Sum Mflops | Sqrt Mflops | Exp Mflops |
| 2x AMD 64 5000+, Ubuntu | JIT 1.6.0_14 | 99 | 43 | 10 |
| GCJ 4.3.2 | 64 | 65 | 13 | |
| 2x Intel Core2 2.4GHz, Ubuntu | JIT 1.6.0_0 | 87.4 | 36.9 | 16.6 |
| GCJ 4.2.4 | 150.6 | 39.3 | 30 | |
| Intel T2600 2.16GHz, Cygwin | JIT 1.6.0_17 | 45.4 | 34.8 | 10.4 |
| GCJ 3.4.4 | 84.1 | 23.7 | 12.1 |
Generally, GCJ beats JIT on numerical computing. However, I have to mention that it takes a lot more time to start the binary generated by GCJ. (I do not know why...)
Here attaches the Java source code (VectorMultiplication.java), which is almost identical to Alex's, but use much shorter vectors (1M v.s. 20M), so more computer can run it.
On my Core2 workstation, the way I invoked GCJ is identical to that used in Alex's experiment:
import java.util.Random;
public class VectorMultiplication {
public static double vector_mul(double a[], double b[], int n, double c[]) {
double s = 0;
for (int i = 0; i < n; ++i)
s += c[i] = a[i] * b[i];
return s;
}
public static void vector_sqrt(double a[], double b[], int n) {
for (int i = 0; i < n; ++i)
b[i] = Math.sqrt(a[i]);
}
public static void vector_exp(double a[], double b[], int n) {
for (int i = 0; i < n; ++i)
b[i] = Math.exp(a[i]);
}
public static void main(String[] args) {
final int MEGA = 1000 * 1000;
Random r = new Random(0);
double a[], b[], c[];
int n = 1 * MEGA;
a = new double[n];
b = new double[n];
c = new double[n];
for (int i = 0; i < n; ++i) {
a[i] = r.nextDouble();
b[i] = r.nextDouble();
c[i] = r.nextDouble();
}
long start = System.currentTimeMillis();
vector_mul(a, b, n, c);
System.out.println("MULT MFLOPS: " +
n/((System.currentTimeMillis() - start)/1000.0)/MEGA);
start = System.currentTimeMillis();
vector_sqrt(c, a, n);
System.out.println("SQRT MFLOPS: " +
n/((System.currentTimeMillis() - start)/1000.0)/MEGA);
start = System.currentTimeMillis();
vector_exp(c, a, n);
System.out.println("EXP MFLOPS: " +
n/((System.currentTimeMillis() - start)/1000.0)/MEGA);
}
}
gcj -O3 -fno-bounds-check -mfpmath=sse -ffast-math -march=native \On my notebooks, I use
--main=VectorMultiplication -o vec-mult VectorMultiplication.java
gcj -O3 -fno-bounds-check -ffast-math \
--main=VectorMultiplication -o vec-mult VectorMultiplication.java
Jan 1, 2010
Learning Java as a C++ Programmer
Primitive Data Types
Classes
- char is 16-bit. byte is 8-bit. boolean corresponds to bool in C++.
- All Java primitive types are signed.Why?
- Java is more strongly typed than C++. No way to convert between boolean and integer types.
- Java has two new operators, >>> and >>>=. Each of these performs a right shift with zero fill.
- Java operators cannot be overloaded, in order to prevent unnecessary bugs
- No struct or union.
- Arrays are objects, defined by Type [].
- Out of index accessing causes ArrayIndexOutOfBoundsException exception.
Classes
- Can set default value of class data members
Subscribe to:
Posts (Atom)
